




Notebooks

Categories



Cells
Premium

BioTuring
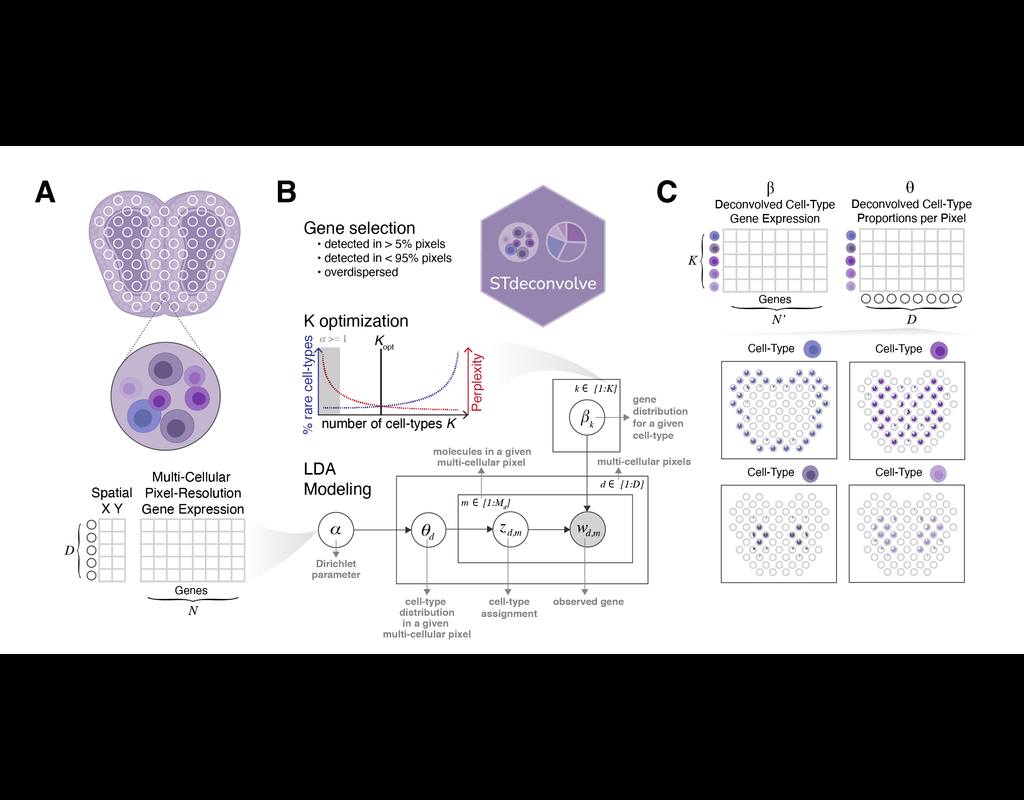
Recent technological advancements have enabled spatially resolved transcriptomic profiling but at multi-cellular pixel resolution, thereby hindering the identification of cell-type-specific spatial patterns and gene expression variation.
To address this challenge, we develop STdeconvolve as a reference-free approach to deconvolve underlying cell types comprising such multi-cellular pixel resolution spatial transcriptomics (ST) datasets. Using simulated as well as real ST datasets from diverse spatial transcriptomics technologies comprising a variety of spatial resolutions such as Spatial Transcriptomics, 10X Visium, DBiT-seq, and Slide-seq, we show that STdeconvolve can effectively recover cell-type transcriptional profiles and their proportional representation within pixels without reliance on external single-cell transcriptomics references.
**STdeconvolve** provides comparable performance to existing reference-based methods when suitable single-cell references are available, as well as potentially superior performance when suitable single-cell references are not available.
STdeconvolve is available as an open-source R software package with the source code available at https://github.com/JEFworks-Lab/STdeconvolve .

BioTuring
The development of large-scale single-cell atlases has allowed describing cell states in a more detailed manner. Meanwhile, current deep leanring methods enable rapid analysis of newly generated query datasets by mapping them into reference atlases.
expiMap (‘explainable programmable mapper’) Lotfollahi, Mohammad, et al. is one of the methods proposed for single-cell reference mapping. Furthermore, it incorporates prior knowledge from gene sets databases or users to analyze query data in the context of known gene programs (GPs).

BioTuring
Advances in multi-omics have led to an explosion of multimodal datasets to address questions from basic biology to translation. While these data provide novel opportunities for discovery, they also pose management and analysis challenges, thus motivating the development of tailored computational solutions. `muon` is a Python framework for multimodal omics.
It introduces multimodal data containers as `MuData` object. The package also provides state of the art methods for multi-omics data integration. `muon` allows the analysis of both unimodal omics and multimodal omics.

BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-cell chromatin data, as an extension of the Seurat R toolkit for single-cell multimodal analysis.
**Signac** enables an end-to-end analysis of single-cell chromatin data, including peak calling, quantification, quality control, dimension reduction, clustering, integration with single-cell gene expression datasets, DNA motif analysis, and interactive visualization.
Furthermore, Signac facilitates the analysis of multimodal single-cell chromatin data, including datasets that co-assay DNA accessibility with gene expression, protein abundance, and mitochondrial genotype. We demonstrate scaling of the Signac framework to datasets containing over 700,000 cells.
Trends
BioTuring
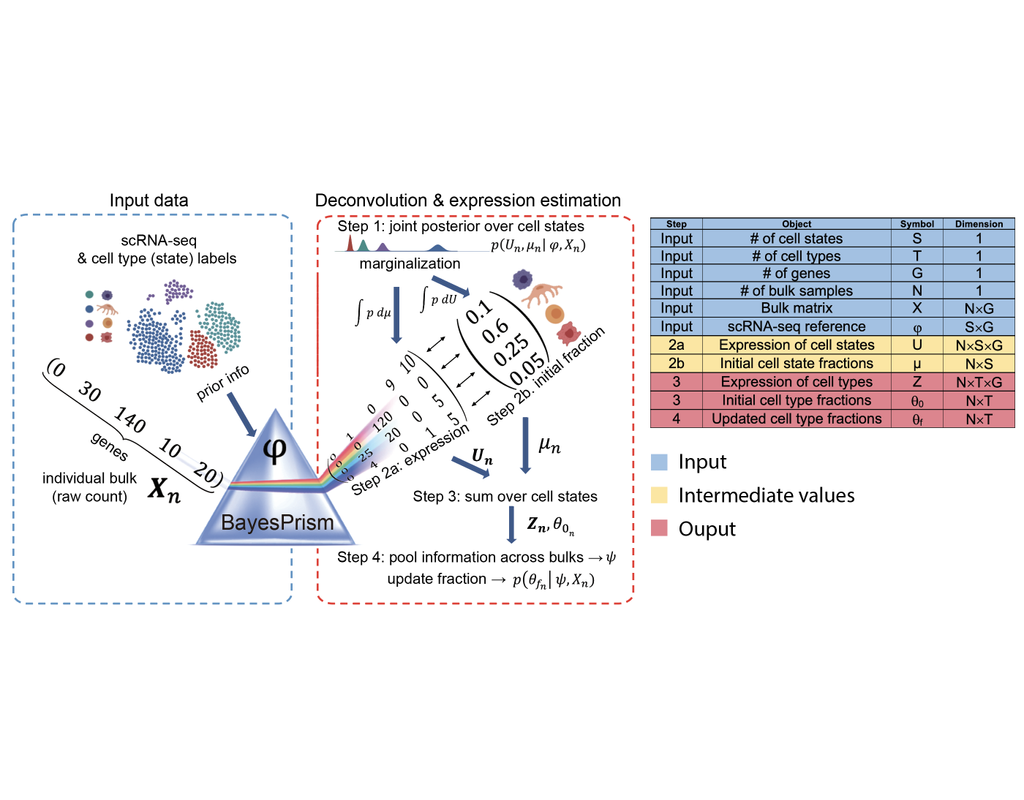
Reconstructing cell type compositions and their gene expression from bulk RNA sequencing (RNA-seq) datasets is an ongoing challenge in cancer research. BayesPrism (Chu, T., Wang, Z., Pe’er, D. et al., 2022) is a Bayesian method used to predict cellular composition and gene expression in individual cell types from bulk RNA-seq datasets, with scRNA-seq as references.
This notebook illustrates an example workflow for bulk RNA-seq deconvolution using BayesPrism. The notebook content is inspired by BayesPrism's vignette and modified to demonstrate how the tool works on BioTuring's platform.